缓存模块
Mybatis作为一个强大的持久层框架,缓存是其必不可少的功能之一。Mybatis中的缓存是两层结构的,分为一级缓存、二级缓存,但在本质上是相同的,它们使用的都是Cache接口的实现。
1. 装饰者模式
2. Cache接口及其实现
Mybatis中缓存模块相应的代码位于cache包下,其中Cache接口是缓存模块中最核心的接口,它定义了所以缓存的基本行为,Cache接口的定义如下:
public interface Cache {
/**
* 该缓存对象的ID
* @return The identifier of this cache
*/
String getId();
/**
* 向缓存中添加数据,一般情况下key是{@link CacheKey} ,value是查询结果
* @param key Can be any object but usually it is a {@link CacheKey}
* @param value The result of a select.
*/
void putObject(Object key, Object value);
/**
* 根据指定的key,在缓存中查找对应的结果对象
* @param key The key
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* 删除key对应的缓存项
* As of 3.3.0 this method is only called during a rollback
* for any previous value that was missing in the cache.
* This lets any blocking cache to release the lock that
* may have previously put on the key.
* A blocking cache puts a lock when a value is null
* and releases it when the value is back again.
* This way other threads will wait for the value to be
* available instead of hitting the database.
*
*
* @param key The key
* @return Not used
*/
Object removeObject(Object key);
/**
* 清空缓存
* Clears this cache instance.
*/
void clear();
/**
* 缓存项的个数,该方法不会被Mybatis核心代码使用,所以可提供空实现
* Optional. This method is not called by the core.
*
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/**
* 获取读写锁,该方法不会被Mybatis核心代码使用,所以可提供空实现
* Optional. As of 3.2.6 this method is no longer called by the core.
* <p>
* Any locking needed by the cache must be provided internally by the cache provider.
*
* @return A ReadWriteLock
*/
default ReadWriteLock getReadWriteLock() {
return null;
}
}
Cache接口的实现类有镀铬,但大部分都是装饰器,只有PrepetualCache提供了Cache接口的基本实现。
2.1. PrepetualCache
PrepetualCache在缓存模块中扮演着ConcreteComponent的角色,其实现比较简单,底层使用HashMap记录缓存项,也是通过该HashMap对象的方法实现的Cache接口中定义的相关方法。PrepetualCache的具体实现如下所示:
/**
* PrepetualCache在缓存模块中扮演着ConcreteComponent的角色,
* 其实比较简单,底层使用HashMap记录缓存项,也是通过该HashMap对象的方法实现的Cache接口中定义的相关方法。
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
private final String id;
/**
* 用于记录缓存项的map对象
*/
private final Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
//下面所有的方法都是通过cache字段记录这个HashMap对象的响应方法实现的
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
//重写了equals()方法和hashCode()方法,两者都只关心id字段,并不关系cache字段
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
下面来介绍cache.decorators包下提供的装饰器,它们都直接实现了Cache接口,扮演着ConcreteDecorator的角色。这些装饰器会在PerpetualCache的基础上提供一些额外的功能,通过多个组合后满足一个特定的需求(比如:二级缓存是,会见到这些装饰器是如何完成动态组合的)。
2.2. BlockingCache
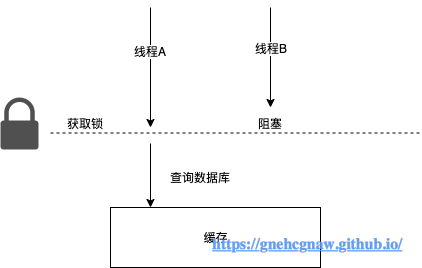
BlockingCache是阻塞版本的缓存装饰器,它会保证只有一个线程到缓存中查找指定key对应的数据。
BlockingCache中各个字段的含义如下所示:
/**
* 阻塞超时时间
*/
private long timeout;
/**
* 被装饰的底层Cache对象
*/
private final Cache delegate;
/**
* 每个key都有对应的ReentrantLock(重入锁)
*/
private final ConcurrentHashMap<Object, ReentrantLock> locks;BlockingCache是如何保证只有一个线程到缓存中查找指定key的,假设线程A在BlockingCache中未查找到keyA对应的缓存项时,线程A会获取keyA对应的锁,这样后续线程在查找keyA时会发生阻塞,如下图所示:
有下面是一个上述情况的例子:
package red.reksai.cache;
import org.apache.ibatis.cache.decorators.BlockingCache;
import org.apache.ibatis.cache.impl.PerpetualCache;
/**
* @author : <a href="mailto:gnehcgnaw@gmail.com">gnehcgnaw</a>
* @since : 2019/12/2 00:44
*/
public class BlockingCacheTest {
public static void main(String[] args) {
MyThread myThread = new MyThread();
Thread thread1 = new Thread(myThread);
Thread thread2 = new Thread(myThread);
thread1.start();
thread2.start();
}
}
class MyThread extends Thread {
public static BlockingCache blockingCache ;
static {
PerpetualCache perpetualCache = new PerpetualCache("namespace1");
perpetualCache.putObject("key","aaa");
blockingCache = new BlockingCache(perpetualCache);
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+">>>>>>"+blockingCache.getObject("key1"));
}
}放入的是key="key",查询的是key="key1"的值,运行结果如下所示:
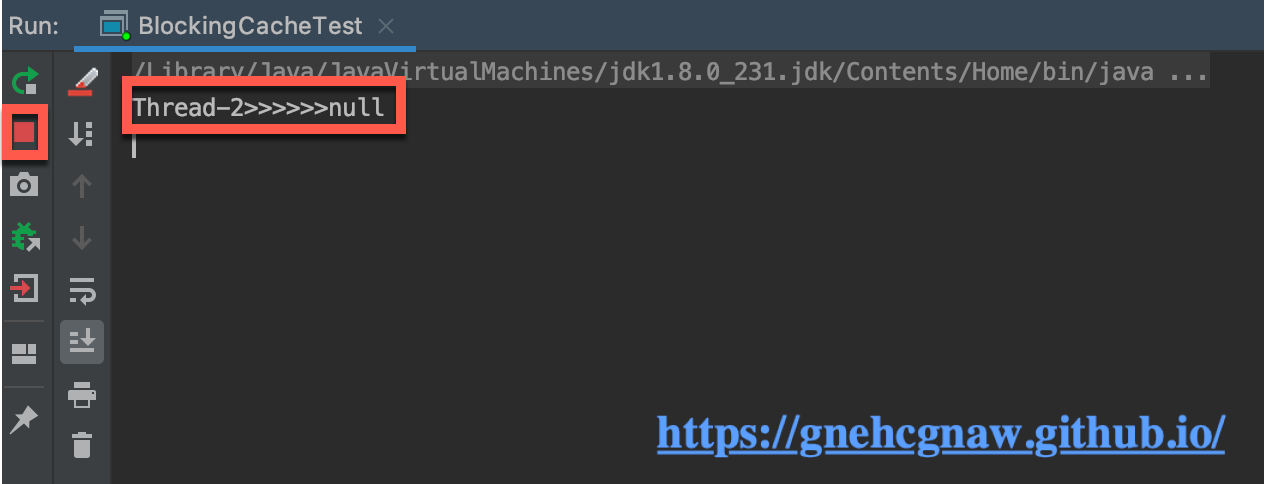
有上图可以发现,只有一个线程执行了,返回的是null,而第二个线程被阻塞了,这是为什么呢?要想解释这个问题只能看BlocklingCache源码了。
2.2.1. getObject()
BlockingCache.getObject()方法的代码如下所示,可以看到在获取指定key对应的对象之前,首先要获取锁,如果查询的结果是不是null,即表明查到了结果,那么释放锁,如果没有查询到结果,后续线程查询就会拿不到锁,因为第一次查询没有查询到结果的情况下并没有去释放锁。
/**
* 获取指定key对应的对象
* @param key The key 要查询的key
* @return key所对应的对象
*/
@Override
public Object getObject(Object key) {
//获取该key对应的锁
acquireLock(key);
Object value = delegate.getObject(key);
if (value != null) {
//释放锁
releaseLock(key);
}
return value;
}2.2.2. acquireLock()
BlockingCache.acquireLock()方法的代码如下所示:
/**
* 尝试获取指定key对应的锁:
* 如果该key没有对应的锁对象则为其创建一个ReetrantLock对象,再加锁;
* 如果获取锁失败,则阻塞一段时间。
* @param key
*/
private void acquireLock(Object key) {
//获取ReentrantLock
Lock lock = getLockForKey(key);
if (timeout > 0) {
try {
//获取锁带超时时长
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
//超时则抛出异常
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
//获取锁,不带超时时长
lock.lock();
}
}2.2.3. getLockForKey()
BlockingCache.getLockForKey()方法的代码如下所示:
/**
* 获取锁,如果该key没有对应的锁对象则为其创建一个ReentrantLock对象
* @param key
* @return
*/
private ReentrantLock getLockForKey(Object key) {
return locks.computeIfAbsent(key, k -> new ReentrantLock());
}看完以上源码,分析:假设线程A从数据库中查找到keyA对应的结果对象后,将结果对象放入到BlockingCache中,此时线程A会释放keyA的对应的锁,唤醒阻塞在该锁上的线程。其他线程即可以从BlockingCache总获取keyA对应的数据,而不是再次访问数据库,具体如下所示:
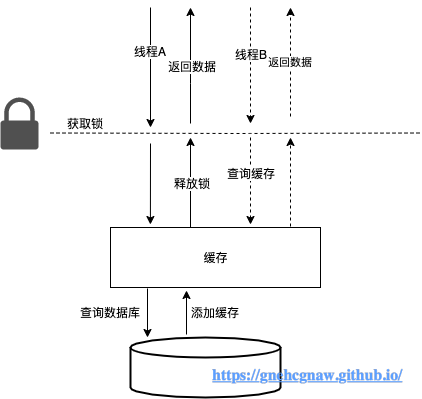
2.3.4. putObject()
BlockingCache.putObject()方法的实现如下所示:
@Override
public void putObject(Object key, Object value) {
try {
//向缓存中添加缓存项
delegate.putObject(key, value);
} finally {
//释放锁
releaseLock(key);
}
}2.3. FifoCache&LruCache
2.3.1. FifoCache
在很多场景下,为了控制缓存的大小,系统需要按照一定的规则清理缓存。FifoCache是先进先出版本的装饰器,当向缓存添加数据时,如果缓存项中的个数已经达到了上线,则会将缓存中最老(即最早进入缓存)的缓存项删除。
FifoCache中各个字段的含义如下:
/**
* 底层被装饰的底层Cache对象
*/
private final Cache delegate;
/**
* 用于记录key进入缓存的先后顺序,使用的是LinkedList<Object>类型的集合对象
*/
private final Deque<Object> keyList;
/**
* 记录缓存项的上线,超过该值,则需要清理最老的缓存项
*/
private int size;FifoCache的getObject()和removerObject()方法的实现都是直接调用底层Cache对象的对应方法。在FifoCache.putObject()方法中会完成缓存项个数的检测以及缓存的清理操作,具体实现如下所示:
@Override
public void putObject(Object key, Object value) {
//检测并清理缓存
cycleKeyList(key);
//条件缓存项
delegate.putObject(key, value);
}
private void cycleKeyList(Object key) {
//记录key
keyList.addLast(key);
//如果达到缓存上线,则清理最老的缓存项
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}2.3.2. LruCache
LruCache是按照近期最少使用算法(Least Recently Used , LRU)进行缓存清理的装饰器,在需要清理换成时,它会清除最近最少使用的缓存项。LruCache中定义的各个字段的含义如下:
/**
* 被装饰的底层Cache对象
*/
private final Cache delegate;
/**
* LinkedHashMap<Object,Object> 类型对象,它是一个有序的HashMap,用于记录key最近的使用情况
*/
private Map<Object, Object> keyMap;
/**
* 记录最少被使用的缓存项的key
*/
private Object eldestKey;LruCache的构造方法默认设置的缓存大小是1024,我们可以通过其setSize()方法重新设置缓存大小,具体实现如下:
/**
* 重置设置缓存大小,
* @param size
*/
public void setSize(final int size) {
//注意LinkedHashMap构造函数的第三个参数,true表示该LinkedHashMap记录的属性是access-order,也就是说LinkedHashMap.get()方法会百变器记录的顺序
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
//当调用LinkedHashMap.put()方法时,会调用该方法
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
//判断hashMap的长度是否大于限定的缓存长度
boolean tooBig = size() > size;
//如果达到缓存上限,后面会删除该项
if (tooBig) {
//获取需要删除的key
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}以上代码涉及到了LinkedHashMap的相关方法,我们可以用一个例子解释:
package red.reksai.javabase;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 高频词汇处理,热度排行
* @author : <a href="mailto:gnehcgnaw@gmail.com">gnehcgnaw</a>
* @since : 2019/12/2 14:38
*/
public class LinkedHashMapTest {
static Object eldKey ;
public static void main(String[] args) {
int size = 3;
LinkedHashMap<String, String > linkedHashMap = new LinkedHashMap<String,String >(size, .75F, true){
@Override
protected boolean removeEldestEntry(Map.Entry<String,String> eldest) {
if (size()>size){
eldKey = eldest.getKey();
}
return size()>size ;
}
};
linkedHashMap.put("1","1");
linkedHashMap.put("2","2");
linkedHashMap.put("3","3");
linkedHashMap.get("1");
System.out.println(linkedHashMap);
linkedHashMap.put("4","4");
System.out.println(linkedHashMap);
}
}
运行结果:
{2=2, 3=3, 1=1}
{3=3, 1=1, 4=4}LruCache就是通过LinkedHashMap的以上特性来确定最久未被使用的缓存项。
LruCache.getObject()方法除了返回缓存项,还会调用keyMap.get()修改key的顺序,表示指定的key最近被使用,具体实现如下所示:
@Override
public Object getObject(Object key) {
//修改LinkedHashMap中记录的顺序
keyMap.get(key);
//返回查询的对象
return delegate.getObject(key);
}
LruCache.putObject()方法畜类添加缓存项,还会将eldsetKey字段指定的缓存项清理掉,具体实现如下所示:
@Override
public void putObject(Object key, Object value) {
//添加缓存项
delegate.putObject(key, value);
//删除最久未使用的缓存项
cycleKeyList(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
//eldestKey不为空表示已达到缓存上限
if (eldestKey != null) {
//删除最久未被使用的缓存项
delegate.removeObject(eldestKey);
eldestKey = null;
}
}2.4. SoftCache&WeakCache
在开始介绍SofrCache和WeakCache实现之前, 先了解Java提供的引用类型,它们分别是强引用(Strong Reference)、软引用(SoftReference)、弱引用(WeakReference)和幽灵引用(Phantom Reference)。
2.4.1. Refernece
2.4.1.1. 强引用
强引用是Java编程中最普遍的引用,例如Object obj = new Object()中,新建的Object对象就是被强引用的。如果一个对象被强引用,即使是Java虚拟机内存空间不足时,GC也绝对不会回收该对象。当Java虚拟机内存不足时,就可能会导致内存溢出,我们常见的就是OutOfMemoryError异常。
2.4.1.2. 软引用
软引用是引用强度仅弱于强引用的一种引用,它使用类SoftReference来表示。当Java虚拟机内存不足时,GC会回收那些只被软引用只想的对象,从而避免内存溢出。在GC释放了那些只被软引用指向的对象之后,虚拟机内存依然不足,才会抛出OutOfMemmoryError异常。软引用适合引用那些可以通过其他方式恢复的对象,例如,数据库缓存中的对象就可以从数据库中恢复,所以软引用可以用来实现缓存,下面将要介绍的SoftCache就是通过软引用实现的。
另外,由于程序使用软引用之前的某个时刻,其所指向的对象可能已经被GC回收掉了,所以通过Reference.get()方法来获取软引用所指向的对象时,总要通过检查该方法返回值是否为null,来判断被软引用的对象是否还存活。
2.4.1.3. 引用队列ReferenceQueue
在很多场景下,我们的程序需要在一个对象的可达性(是否已经被GC回收)发生变化时得到通知,引用队列就是用于收集这些信息的队列。在创建SoftReference对象时,可以为其关联一个引用队列,当SoftReference所引用的对象被GC回收时,Java虚拟机就会将该SoftReference对象添加到与之关联的引用队列中。当需要检测这些通知信息时,就可以从引用队列中获取这些SoftReference对象。不仅是SoftReference对象,下面介绍的弱引用和幽灵引用都可以关联相应的队列。
2.4.1.4. 弱引用
弱引用的强度比软引用的强度还弱。弱引用使用WeakReference来表示,它可以引用一个对象,但并不阻止被引用的对象被GC回收。在虚拟机进行GC时,如果指向了一个对象的所有引用都是弱引用,那么该对象会被回收。由此可见,只被弱引用所指向的对象的生命周期是两次GC之间的这段时间。而只被软引用所指向的对象可以经历多次GC,知道出现内存紧张的情况才被回收。
弱引用典型的应用场景就是JDK提供的java.util.WeakHashMap。WeakHashMap.Entity实现继承了WeakReference。Entity弱引用key,强引用vaule。如图所示:

当不再有强引用指向key的时候,则key可以被垃圾回收,当key被垃圾回收之后,对应的Entity对象也会被Java虚拟机加入到其他关联队列中。当应用程序瑕疵操作WeakHashMap时,例如对WeakHashMap的扩容操作,就会遍历关联的引用队列,将其中的Entity对象从WeakHashMap中删除。
2.4.1.5. 幽灵引用
在介绍幽灵引用的时候,要先了解一下Java提供的对象终止化机制。在Object类里面有一个finalize()方法,设计该方法的初衷是在一个对象被真正回收之前,执行一些清理工作,但是GC的运行时间是不确定的,所以这些清理工作的实际运行时间也是无法预知的,而且JVM虚拟机不能保证finalize()方法一定会被调用。每个对象的finalize()方法至多由GC执行一次,对于再生对象GC不会再次调用其finalize()方法。另外,使用finalize()方法还会导致严重的内存消耗和性能损失。由于finalize()方法存在的种种问题,该方法现在已经被废弃,而我们可以使用幽灵引用实现其代替方案。
幽灵引用,又叫“虚引用”,它是最弱的一种引用类型, 有类PhantomReference表示。在引用对象被GC回收时,调用签名介绍的SoftReference以及WeakReference的get()方法,得到的是其引用的对象;当引用的对象已经被GC回收时,则得到null。但是PhantomReference.get()方法始终返回null。
在创建幽灵引用的时候必须要指定一个引用队列。当GC准备回收一个对象的时候,如果发现它还是幽灵引用,就会在回收对象的内存之前,把该虚引用加入到与之关联的引用队列中。程序可以通过检查该引用队列里面的内容,跟踪对象是否已经被回收并惊醒一些清理工作。幽灵引用还可以用来实现比较精细的内存使用控制,例如应用程序可以在确定一个对象要被回收之后,再申请内存创建对象,但这种需求并不多见。
介绍完Java提供的四种引用类型,我们来介绍SoftCache的实现。
2.4.2. SoftCache
SoftCache中各个字段的含义如下所示:
3. CacheKey
在Cache中唯一确定一个缓存项需要使用缓存项的key,Mybatis中因为涉及到动态SQL等方面的因素,其缓存的key不能仅仅通过一个String表示,所以Mybatis提供了CacheKey类来表示缓存项的key,在一个Cachekey对象中可以封装多个影响缓存项的因素。
CacheKey中可以添加多个对象,有这些对象共同确定两个CacheKey对象是否相同。
CacheKey中核心字段的含义和功能如下所示:
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!