构建语句
在进行解析Mapper映射配置文件的时候,还有一类比较重要的节点需要解析,也就是本节将要介绍的SQL节点。这些SQL节点主要用于定义SQL语句,它们不在有XMLMapperBuilder进行解析,而是有XMLStatementBuilder负责进行解析。
1. XMLStatementBuilder
下面开始分析其解析SQL相关节点的过程,XMLStatementBuilder.parseStatementNode()方法是解析SQL节点的入口函数,其具体实现如下所示,我将会按照图中标记的步骤分析:
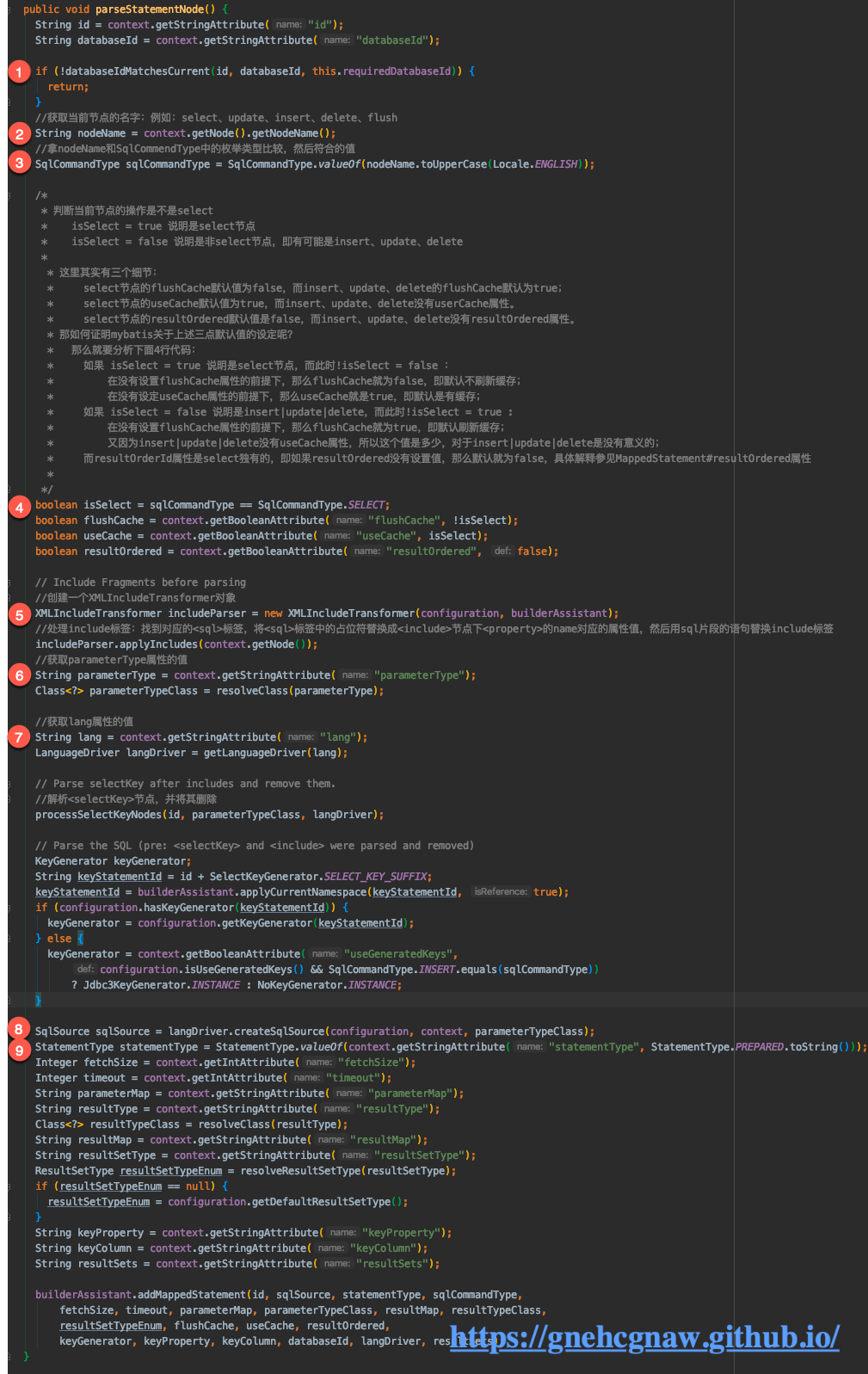
步骤1:首先判断Configuration.databaseId和select、update、insert、delete标签中配置的databaseId是否一致,如果一致就进行下面的步骤,如果不一致就直接跳出,说白了就是:Mapper映射配置文件都会被加载,但是Mapper映射配置文件的节点有可能不会被解析,这些节点是select、update、insert、delete还有上节说的sql,涉及到的代码如下所示:
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}步骤二、步骤三:获取节点名称,然后跟枚举类SqlCommand中的属性进行比较,返回指定枚举值的对象,SqlCommand代码如下所示:
/**
* SQL命令的类型
* @author Clinton Begin
*/
public enum SqlCommandType {
UNKNOWN, INSERT, UPDATE, DELETE, SELECT, FLUSH
}
步骤二涉及到的代码如下所示:
//获取当前节点的名字:例如:select、update、insert、delete、flush
String nodeName = context.getNode().getNodeName();
//拿nodeName和SqlCommendType中的枚举类型比较,然后符合的值
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));步骤四:解析节点中的flushCache、useCache、resultOrdered属性,涉及到的代码如下所示:
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);这段代码看着稀松平常,但是我看到了代码艺术。
步骤五:在解析语句之前,先创建XMLIncludeTransformer对象,利用XMLIncluderTransformer.appleIncludes()去解析<include>节点。
// Include Fragments before parsing
//创建一个XMLIncludeTransformer对象
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
//处理include标签:找到对应的<sql>标签,将<sql>标签中的占位符替换成<include>节点下<property>的name对应的属性值,然后用sql片段的语句替换include标签
includeParser.applyIncludes(context.getNode());1.1. 解析<include>节点
在解析SQL节点之前,首先通过XMLIncloudeTransformer解析SQL语句中的<include>节点,该解析过程在XMLIncludeTransformer.applyIncluders()方法实现的:
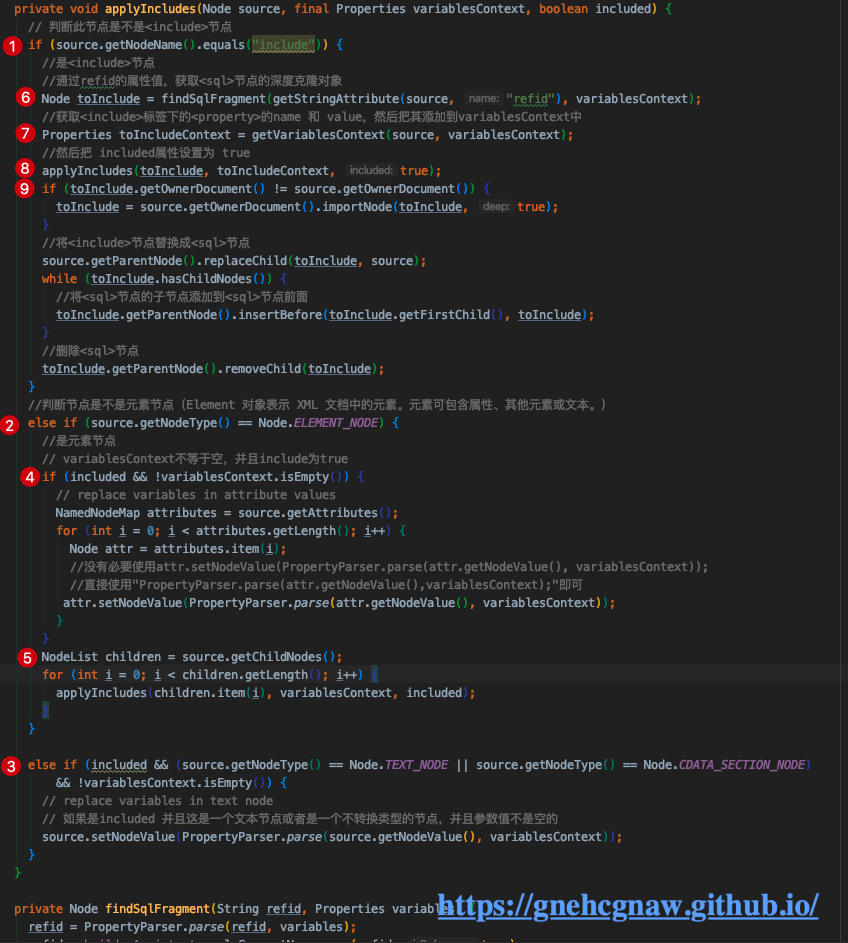
public void applyIncludes(Node source) {
Properties variablesContext = new Properties();
//获取mybatis-config.xml中,<properties>节点中定义的变量集合
Properties configurationVariables = configuration.getVariables();
/*
* 下面的一行代码其实就是说,如果configurationVariables不为null,那么就把值赋给variablesContext。
* if(configurationVariables!=null){
* variablesContext.putAll(configurationVariables)
* }
*/
Optional.ofNullable(configurationVariables).ifPresent(variablesContext::putAll);
//处理<include>节点
applyIncludes(source, variablesContext, false);
}下面是处理<include>节点的applyIncludes()方法重载:
通过示例去解读代码,具体示例如下所示:
<select id="selectBlogList" resultType="map">
select *
<include refid="fromSqlElement">
<property name="tablename" value="tb_blog"/>
</include>
</select>
<sql id="fromSqlElement">
from ${tablename}
<include refid="whereSqlElement">
<property name="idValue" value="1"/>
</include>
</sql>
<sql id="whereSqlElement">
where blog_id = ${idValue}
</sql>从步骤一开始,因为当前解析的是<select>节点,并且<select>节点是一个Node.ElEMENT_NODE,所以会进入到步骤二;
然后进行步骤四,判断include=true&&variableContext!=null是否成立,因为此时的include是false,所以不成立,这时候程序直接进入步骤五;
步骤五是获取所有的子节点,然后遍历,一个个从步骤一执行;
当前<select id="selectBlogList" resultType="map">下是有三个节点的,分别是:
故:
第一次循环去执行步骤一的是:节点值为\n select \n的节点;
- 此时程序会进入步骤三,因为
included=false,所以直接跳出;
第二次循环去执行步骤一的是:节点<include>,因为节点的名称等于include,所以会进入步骤一中的代码;
步骤六:获取<include>上的refid属性的值,然后把这个值作为参数调用findSqlFragment()方法,获取refid值相应的<sql>节点对象,此时获取的节点对象如下所示:
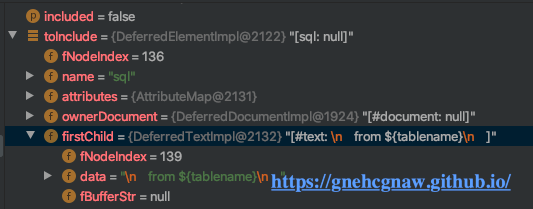
其实就是XML中的以下代码段:
<sql id="fromSqlElement">
from ${tablename}
<include refid="whereSqlElement">
<property name="idValue" value="1"/>
</include>
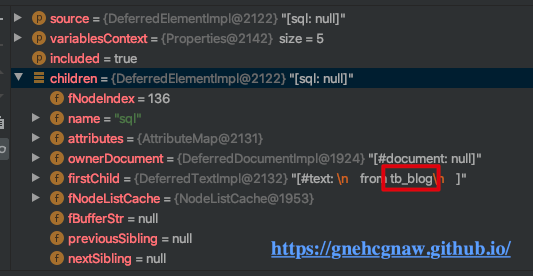
</sql>接着,执行步骤七,通过调用getVariablesContext()方法获取<include>标签下的<property>的name和value,并将其添加到variableContext;
步骤八:将included设置为ture,表示<select>下<include>下<property>的属性值已经解析,接着会调到步骤四,执行步骤4中的代码,然后使用property中的属性值替换,如下图所示:
最后最后一个值也被解析出来:
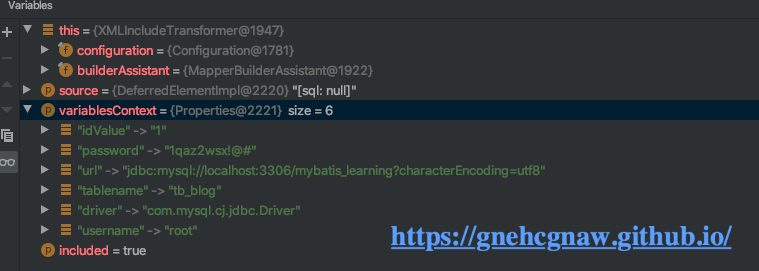
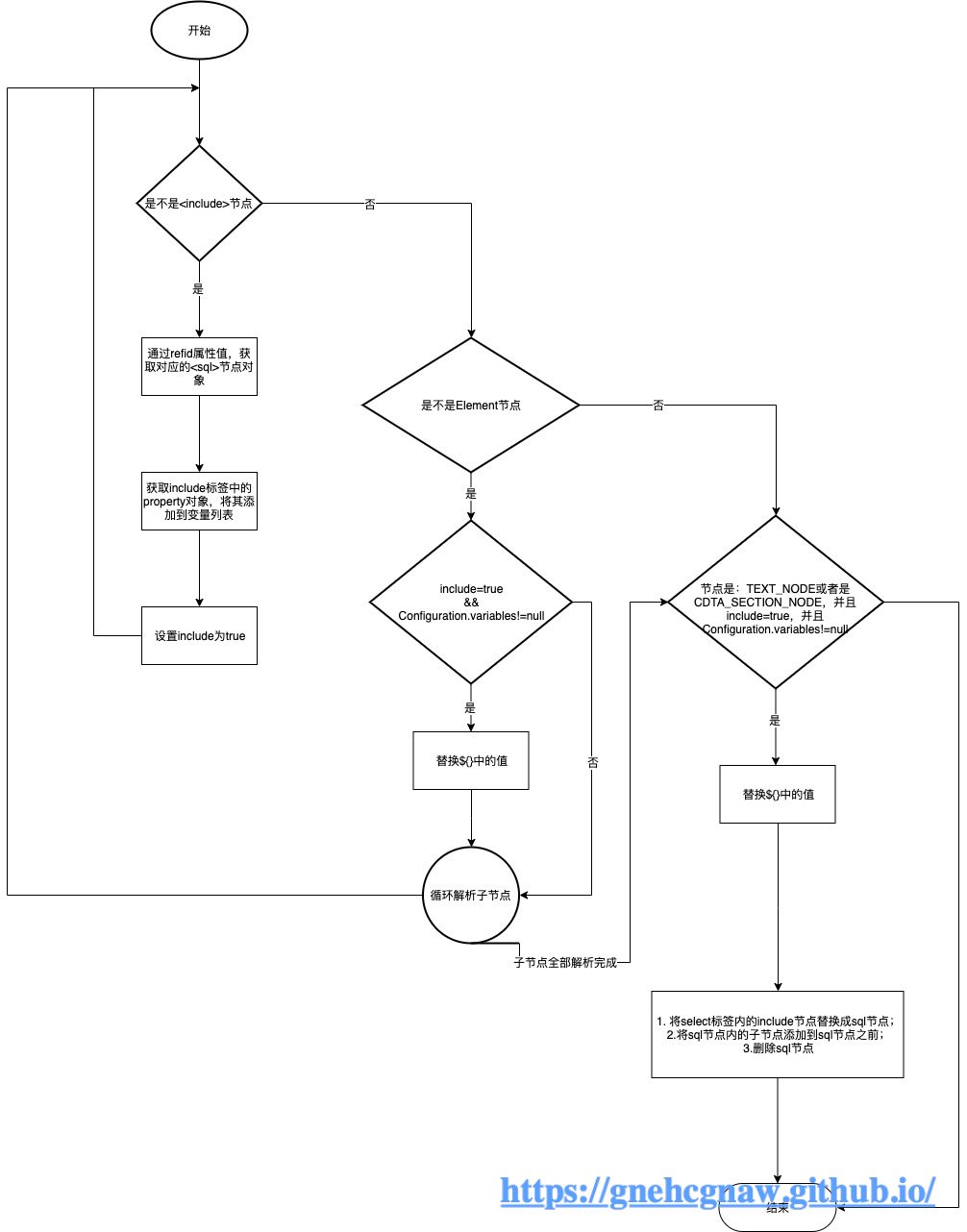
说白了<include>和<sql>节点可以配合使用,多层嵌套,实现更加复杂的SQL片段的重用,这样的话,解析过程就会递归更多层,流程也会变得更加复杂, 但是本质和上述分析是一样的,我总结出来流程如下所示:
最后处理完的select节点中的语句的样子,如下所示:
select *
from tb_blog
where blog_id = #{id}1.2. 解析<selectKey>节点
<selectKey>节点可以定义的属性和子节点,如下所示:
<!ELEMENT selectKey (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*>
<!ATTLIST selectKey
resultType CDATA #IMPLIED
statementType (STATEMENT|PREPARED|CALLABLE) #IMPLIED
keyProperty CDATA #IMPLIED
keyColumn CDATA #IMPLIED
order (BEFORE|AFTER) #IMPLIED
databaseId CDATA #IMPLIED
>在<insert>、<update>节点中可以定义<selectKey>节点来解决主键自增问题,<selectKey>节点对应的KeyGenerator接口会在后面详细介绍,这里关注<selectKey>节点的解析。
XMLStatementBuilder.processSelectKeyNodes()方法负责解析SQL节点中的<selectKey>子节点,具体代码如下所示:
private void processSelectKeyNodes(String id, Class<?> parameterTypeClass, LanguageDriver langDriver) {
//获取所有的selectKey节点
List<XNode> selectKeyNodes = context.evalNodes("selectKey");
//解析<selectKey>节点
if (configuration.getDatabaseId() != null) {
parseSelectKeyNodes(id, selectKeyNodes, parameterTypeClass, langDriver, configuration.getDatabaseId());
}
parseSelectKeyNodes(id, selectKeyNodes, parameterTypeClass, langDriver, null);
//移除<selectKey>节点
removeSelectKeyNodes(selectKeyNodes);
}在parseSelectKeyNode()方法中,首先读取<selectKey>节点的一系列属性,然后调用LanguageDriver.createSqlSource()方法创建对应的SqlSource对象,最后创建MapperStatement对象,并添加到Configuraiton.mappedStatements集合中保存。parseSelectKeyNode()方法的具体实现如下:
private void parseSelectKeyNode(String id, XNode nodeToHandle, Class<?> parameterTypeClass, LanguageDriver langDriver, String databaseId) {
//获取<selectKey>节点下的resultType、statementType、keyProperty、keyColumn、order属性的值
String resultType = nodeToHandle.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
StatementType statementType = StatementType.valueOf(nodeToHandle.getStringAttribute("statementType", StatementType.PREPARED.toString()));
String keyProperty = nodeToHandle.getStringAttribute("keyProperty");
String keyColumn = nodeToHandle.getStringAttribute("keyColumn");
boolean executeBefore = "BEFORE".equals(nodeToHandle.getStringAttribute("order", "AFTER"));
//defaults
//设置一些MappedStatement对象需要的默认配置,
boolean useCache = false;
boolean resultOrdered = false;
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
Integer fetchSize = null;
Integer timeout = null;
boolean flushCache = false;
String parameterMap = null;
String resultMap = null;
ResultSetType resultSetTypeEnum = null;
//通过LanguageDriver.createSqlSource()方法生成SqlSource
SqlSource sqlSource = langDriver.createSqlSource(configuration, nodeToHandle, parameterTypeClass);
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
//然后把解析出来的<selectKey>下面的语句构建成MappedStatement对象
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, null);
id = builderAssistant.applyCurrentNamespace(id, false);
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
//创建<selectKey>节点对应的KeyGenerator,添加到Configuration.keyGenerators集合中
configuration.addKeyGenerator(id, new SelectKeyGenerator(keyStatement, executeBefore));
}1.3. 初始化KeyGenerator
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}1.4. 创建SqlSource
1.4.1. LangDriver
Pluggable Scripting Languages For Dynamic SQL
Starting from version 3.2 MyBatis supports pluggable scripting languages, so you can plug a language driver and use that language to write your dynamic SQL queries.
You can plug a language by implementing the following interface:
public interface LanguageDriver { ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql); SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType); SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType); }Once you have your custom language driver you can set it to be the default by configuring it in the
mybatis-config.xmlfile:<typeAliases> <typeAlias type="org.sample.MyLanguageDriver" alias="myLanguage"/> </typeAliases> <settings> <setting name="defaultScriptingLanguage" value="myLanguage"/> </settings>Instead of changing the default, you can specify the language for an specific statement by adding the
langattribute as follows:<select id="selectBlog" lang="myLanguage"> SELECT * FROM BLOG </select>Or, in the case you are using mappers, using the
@Langannotation:public interface Mapper { @Lang(MyLanguageDriver.class) @Select("SELECT * FROM BLOG") List<Blog> selectBlog(); }NOTE You can use Apache Velocity as your dynamic language. Have a look at the MyBatis-Velocity project for the details.
All the xml tags you have seen in the previous sections are provided by the default MyBatis language that is provided by the driver
org.apache.ibatis.scripting.xmltags.XmlLanguageDriverwhich is aliased asxml.
LanguageDriver接口有两个实现类,如下图所示:
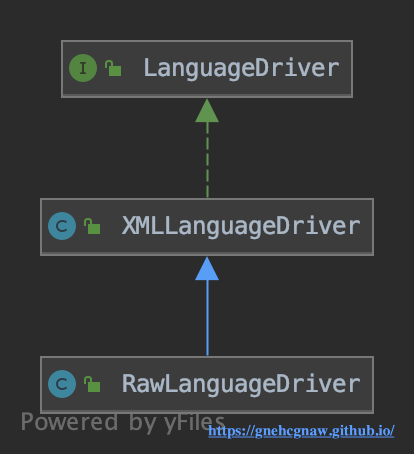
在Configuration的构造方法中,可以看到如下的代码段,由此可见默认使用的是XMLLanguageDriver实现类。
//设置了默认的语言驱动程序为XMLLanguageDriver
languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
languageRegistry.register(RawLanguageDriver.class);在XMLLanguageDriver.createSqlSouece()方法中创建XMLScriptBuilder对象并调用XMLScriptBuilder.parseScriptNode()方法创建SqlSouece对象。
//处理xml中的SqlSource
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
//创建XMLScriptBuilder对象
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
//调用XMLScriptBuilder.parseScriptNode()方法创建SqlSource对象
return builder.parseScriptNode();
}
//处理Mapper接口注解中的SqlSource
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
// issue #3
if (script.startsWith("<script>")) {
XPathParser parser = new XPathParser(script, false, configuration.getVariables(), new XMLMapperEntityResolver());
return createSqlSource(configuration, parser.evalNode("/script"), parameterType);
} else {
// issue #127
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
} else {
return new RawSqlSource(configuration, script, parameterType);
}
}
} @Lang(XMLLanguageDriver.class)
@Select("SELECT firstName, lastName FROM names WHERE lastName LIKE #{name} and 0 < 1")
List<Name> selectXmlWithMapperAndSqlSymbols(Parameter p);2. XMLScriptBuilder
XMLScriptBuild的属性如下所示:
/**
* 要解析的节点
*/
private final XNode context;
/**
* 是否是动态节点
*/
private boolean isDynamic;
/**
* 参数类型
*/
private final Class<?> parameterType;
/**
* NodeHandler的map集合
*/
private final Map<String, NodeHandler> nodeHandlerMap = new HashMap<>();XMLScriptBuild在初始化的时候,首先会调用父类的构造方法初始化一些参数,然后还会调用本身的initNodeHandlerMap()为XMLScriptBuilder.nodeHandlerMap赋值,具体如下所示:
public XMLScriptBuilder(Configuration configuration, XNode context, Class<?> parameterType) {
super(configuration);
this.context = context;
this.parameterType = parameterType;
initNodeHandlerMap();
}
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
2.1. praseScriptNode()
public SqlSource parseScriptNode() {
//判断当前的节点是不是动态SQL,动态SQL会包括占位符或是动态SQL相关的节点
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
//根据是否是动态SQL,创建相应的SqlSource对象
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}这里的isDynamic会被调用parseDynamicTags()重新赋值,而在这里会判断整个SQL节点是不是动态的,如果不是动态的SQL节点,则创建相应的RawSqlSource对象。
这里有个细节:
根据isDynamic值不同生成不同的SqlSource实现类,为true的时候生成DynamicSqlSource对象,为false的时候生成RawSqlSource对象,但是根据DynamicSqlSource和RawSqlSource构造方法的不同的原因,可以发现在isDynamic=true的时候,只是单单生成了一个DynamicSqlSource对象,而当isDynamic=false的时候,RawSqlSource的构造方法中还调用了RawSqlSource.geSql()完成了SQL的拼接,接着又通过SqlSourceBuilder.parse()完成了SQL中“#{}”到“?”的转变。(DynamicSqlSource的构造方法和RawSqlSource的构造方法,参见SqlSource&SqlNode章节)
2.1. parseDynamicTags()
是否是动态语句的规则就是:如果节点中只包含#{}占位符,而不包含动态SQL节点或未被解析的${}占位符的话,则不是动态SQL语句,会创建相应的StaticTextSqlNode对象。
protected MixedSqlNode parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
//创建XNode,该过程会将能解析掉的${}都解析掉
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
//解析SQL语句,如果含有未解析的“${}”占位符,则为动态SQL
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
//标记为动态SQL语句
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
}
// issue #628
else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) {
//如果节点时一个标签,那么一定是动态SQL,并且根据不同的动态标签生成不同的NodeHandler
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
//处理动态SQL,并将解析得到的SQLNode对象放入contents集合中t保存
handler.handleNode(child, contents);
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}上面遇到的TextNode、StaticTextSqlNode等都是SqlNode接口的实现。SqlNode接口的每个实现都对应于不同的SQL节点类型,每个实现的具体代码后面遇到了再详细介绍。
TextSqlNode.isDynamic()方法通过DynamicCheckerTokenParser和GenericTokenParser配合解析文本节点,并判断它是否为动态SQL,该方法具体的实现如下所示:
public boolean isDynamic() {
DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
//创建通用占位符解析器GenericTokenParser
GenericTokenParser parser = createParser(checker);
parser.parse(text);
return checker.isDynamic();
} private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}在解析标签的时候,如果标签下还存在其他标签,则会从XMLScriptBuilder.nodeHandlerMap中根据标签名称获取对应的NodeHandler对象,具体实现如下所示:
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);3. NodeHandler
NodeHandler接口的实现如下图所示:
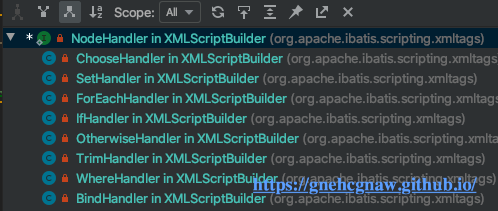
NodeHandler接口的实现类会对不同的动态SQL标签进行解析,生成对应的SqlNode对象,并将其添加到contents集合中,这里以ForEachHandler为例进行分析,具体实现如下所示:
private class ForEachHandler implements NodeHandler {
public ForEachHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
//解析节点的子节点
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
String collection = nodeToHandle.getStringAttribute("collection");
String item = nodeToHandle.getStringAttribute("item");
String index = nodeToHandle.getStringAttribute("index");
String open = nodeToHandle.getStringAttribute("open");
String close = nodeToHandle.getStringAttribute("close");
String separator = nodeToHandle.getStringAttribute("separator");
//创建ForEachSqlNode对象,并将其添加到targetContents集合中
ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, index, item, open, close, separator);
targetContents.add(forEachSqlNode);
}
}
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!